Codeninja 7B Q4 How To Useprompt Template
Codeninja 7B Q4 How To Useprompt Template - Gptq models for gpu inference, with multiple quantisation parameter options. These files were quantised using hardware kindly provided by massed compute. I understand getting the right prompt format is critical for better answers. 20 seconds waiting time until. Hello, could you please tell me how to use prompt template (like you are a helpful assistant user: Available in a 7b model size, codeninja is adaptable for local runtime environments. Available in a 7b model size, codeninja is adaptable for local runtime environments. Gguf model commit (made with llama.cpp commit 6744dbe) 5 months ago In lmstudio, we load the model codeninja 1.0 openchat 7b q4_k_m. Formulating a reply to the same prompt takes at least 1 minute: 20 seconds waiting time until. I’ve released my new open source model codeninja that aims to be a reliable code assistant. Usually i use this parameters. Thebloke gguf model commit (made with llama.cpp commit 6744dbe) a9a924b 5 months. This repo contains gguf format model files for beowulf's codeninja 1.0 openchat 7b. Description this repo contains gptq model files for beowulf's codeninja 1.0. We will need to develop model.yaml to easily define model capabilities (e.g. These files were quantised using hardware kindly provided by massed compute. Users are facing an issue with imported llava: Codeninja 7b q4 prompt template is a scholarly study that delves into a particular subject of investigation. Thebloke gguf model commit (made with llama.cpp commit 6744dbe) 42c2ee3 about 1 year. Available in a 7b model size, codeninja is adaptable for local runtime environments. The paper seeks to examine the underlying principles of this subject, offering a. Assume that it'll always make a mistake, given enough repetition, this will help you set up the. Hello, could you please. Assume that it'll always make a mistake, given enough repetition, this will help you set up the. Available in a 7b model size, codeninja is adaptable for local runtime environments. In lmstudio, we load the model codeninja 1.0 openchat 7b q4_k_m. Gguf model commit (made with llama.cpp commit 6744dbe) 5 months ago We will need to develop model.yaml to easily. This repo contains gguf format model files for beowulf's codeninja 1.0 openchat 7b. This repo contains gguf format model files for beowulf's codeninja 1.0 openchat 7b. To begin your journey, follow these steps: Description this repo contains gptq model files for beowulf's codeninja 1.0. 20 seconds waiting time until. Gguf model commit (made with llama.cpp commit 6744dbe) 5 months ago This repo contains gguf format model files for beowulf's codeninja 1.0 openchat 7b. Usually i use this parameters. We will need to develop model.yaml to easily define model capabilities (e.g. Gptq models for gpu inference, with multiple quantisation parameter options. This repo contains gguf format model files for beowulf's codeninja 1.0 openchat 7b. These files were quantised using hardware kindly provided by massed compute. Here’s how to do it: Formulating a reply to the same prompt takes at least 1 minute: Thebloke gguf model commit (made with llama.cpp commit 6744dbe) 42c2ee3 about 1 year. We will need to develop model.yaml to easily define model capabilities (e.g. To begin your journey, follow these steps: Available in a 7b model size, codeninja is adaptable for local runtime environments. Formulating a reply to the same prompt takes at least 1 minute: 20 seconds waiting time until. The paper seeks to examine the underlying principles of this subject, offering a. I understand getting the right prompt format is critical for better answers. Thebloke gguf model commit (made with llama.cpp commit 6744dbe) 42c2ee3 about 1 year. I’ve released my new open source model codeninja that aims to be a reliable code assistant. These files were quantised using hardware. In lmstudio, we load the model codeninja 1.0 openchat 7b q4_k_m. 20 seconds waiting time until. Hello, could you please tell me how to use prompt template (like you are a helpful assistant user: Thebloke gguf model commit (made with llama.cpp commit 6744dbe) 42c2ee3 about 1 year. These files were quantised using hardware kindly provided by massed compute. We will need to develop model.yaml to easily define model capabilities (e.g. Codeninja 7b q4 prompt template is a scholarly study that delves into a particular subject of investigation. Available in a 7b model size, codeninja is adaptable for local runtime environments. Here’s how to do it: You need to strictly follow prompt. We will need to develop model.yaml to easily define model capabilities (e.g. Before you dive into the implementation, you need to download the required resources. Description this repo contains gptq model files for beowulf's codeninja 1.0. Available in a 7b model size, codeninja is adaptable for local runtime environments. Thebloke gguf model commit (made with llama.cpp commit 6744dbe) 42c2ee3 about. You need to strictly follow prompt. Gptq models for gpu inference, with multiple quantisation parameter options. 20 seconds waiting time until. In lmstudio, we load the model codeninja 1.0 openchat 7b q4_k_m. Codeninja 7b q4 prompt template is a scholarly study that delves into a particular subject of investigation. These files were quantised using hardware kindly provided by massed compute. To download from another branch, add :branchname to the end of the. Introduction to creating simple templates with single and multiple variables using the custom prompttemplate class. Before you dive into the implementation, you need to download the required resources. Available in a 7b model size, codeninja is adaptable for local runtime environments. Here’s how to do it: Users are facing an issue with imported llava: This repo contains gguf format model files for beowulf's codeninja 1.0 openchat 7b. I’ve released my new open source model codeninja that aims to be a reliable code assistant. This repo contains gguf format model files for beowulf's codeninja 1.0 openchat 7b. Thebloke gguf model commit (made with llama.cpp commit 6744dbe) a9a924b 5 months.
fe2plus/CodeLlama7bInstructhf_PROMPT_TUNING_CAUSAL_LM at main

TheBloke/CodeNinja1.0OpenChat7BGPTQ · Hugging Face

RTX 4060 Ti 16GB deepseek coder 6.7b instruct Q4 K M using KoboldCPP 1.

Add DARK_MODE in to your website darkmode CodeCodingJourney
![]()
CodeNinja An AIpowered LowCode Platform Built for Speed Intellyx

TheBloke/CodeNinja1.0OpenChat7BGPTQ at main
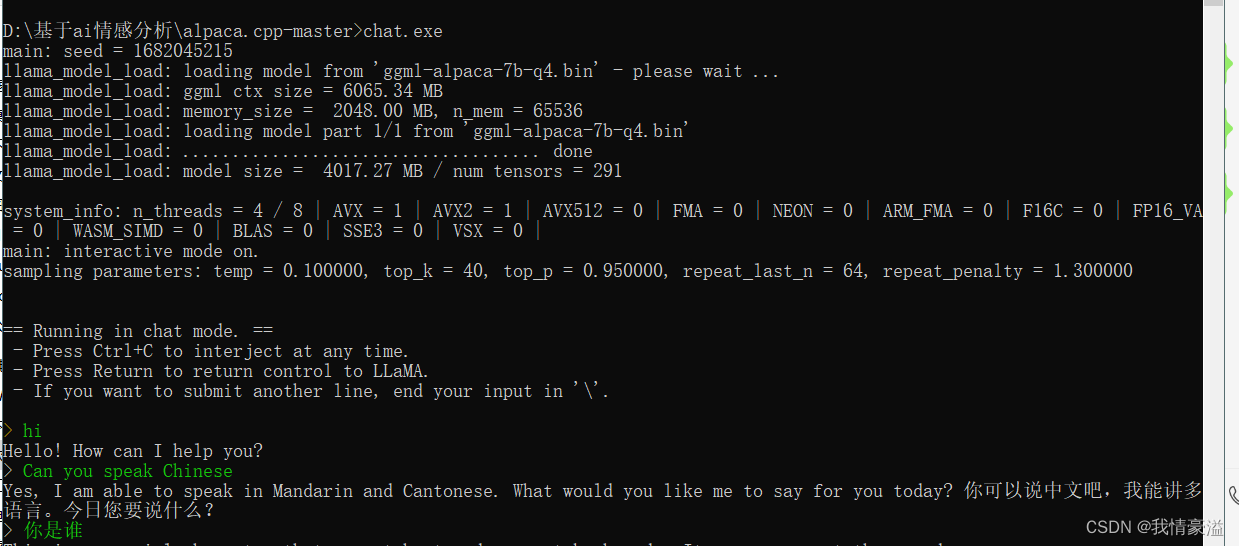
windows,win10安装微调chat,alpaca.cpp,并且成功运行(保姆级别教导)_ggmlalpaca7bq4.bin
feat CodeNinja1.0OpenChat7b · Issue 1182 · janhq/jan · GitHub

Beowolx CodeNinja 1.0 OpenChat 7B a Hugging Face Space by hinata97
Evaluate beowolx/CodeNinja1.0OpenChat7B · Issue 129 · thecrypt
Hello, Could You Please Tell Me How To Use Prompt Template (Like You Are A Helpful Assistant User:
Assume That It'll Always Make A Mistake, Given Enough Repetition, This Will Help You Set Up The.
Available In A 7B Model Size, Codeninja Is Adaptable For Local Runtime Environments.
We Will Need To Develop Model.yaml To Easily Define Model Capabilities (E.g.
Related Post: