Glm4 Invalid Conversation Format Tokenizerapplychattemplate
Glm4 Invalid Conversation Format Tokenizerapplychattemplate - # main logic to handle different conversation formats if isinstance (conversation, list ) and all ( isinstance (i, dict ) for i in conversation): The issue seems to be unrelated to the server/chat template and is instead caused by nans in large batch evaluation in combination with partial offloading (determined with llama. I tried to solve it on my own but. Query = 你好 inputs = tokenizer. As of transformers v4.44, default chat template is no longer allowed, so you must provide a chat template if the tokenizer does not. But recently when i try to run it again it suddenly errors:attributeerror: Upon making the request, the server logs an error related to the conversation format being invalid. I created formatting function and mapped dataset already to conversational format: Verify that your api key is correct and has not expired. Specifically, the prompt templates do not seem to fit well with glm4, causing unexpected behavior or errors. Cannot use apply_chat_template () because tokenizer.chat_template is not set. My data contains two key. Verify that your api key is correct and has not expired. Below is the traceback from the server: # main logic to handle different conversation formats if isinstance (conversation, list ) and all ( isinstance (i, dict ) for i in conversation): I want to submit a contribution to llamafactory. The issue seems to be unrelated to the server/chat template and is instead caused by nans in large batch evaluation in combination with partial offloading (determined with llama. Query = 你好 inputs = tokenizer. As of transformers v4.44, default chat template is no longer allowed, so you must provide a chat template if the tokenizer does not. Import os os.environ ['cuda_visible_devices'] = '0' from. My data contains two key. Union[list[dict[str, str]], list[list[dict[str, str]]], conversation], # add_generation_prompt: Cannot use apply_chat_template because tokenizer.chat_template is. 'chatglmtokenizer' object has no attribute 'sp_tokenizer'. Query = 你好 inputs = tokenizer. 微调脚本使用的官方脚本,只是对compute metrics进行了调整,不应该对这里有影响。 automodelforcausallm, autotokenizer, evalprediction, The text was updated successfully, but these errors were. Result = handle_single_conversation(conversation.messages) input_ids = result[input] input_images. Cannot use apply_chat_template because tokenizer.chat_template is. Union[list[dict[str, str]], list[list[dict[str, str]]], conversation], # add_generation_prompt: Raise valueerror(invalid conversation format) content = self.build_infilling_prompt(message) input_message = self.build_single_message(user, ,. My data contains two key. My data contains two key. The text was updated successfully, but these errors were. Cannot use apply_chat_template because tokenizer.chat_template is. 微调脚本使用的官方脚本,只是对compute metrics进行了调整,不应该对这里有影响。 automodelforcausallm, autotokenizer, evalprediction, But recently when i try to run it again it suddenly errors:attributeerror: Here is how i’ve deployed the models: Raise valueerror(invalid conversation format) content = self.build_infilling_prompt(message) input_message = self.build_single_message(user, ,. I created formatting function and mapped dataset already to conversational format: Cannot use apply_chat_template because tokenizer.chat_template is. I am trying to fine tune llama3.1 using unsloth, since i am a newbie i am confuse about the tokenizer and prompt templete related codes and format. As of transformers v4.44, default chat template is no longer allowed, so you must provide a chat template if the tokenizer does not. My data contains two. I created formatting function and mapped dataset already to conversational format: Obtain a new key if necessary. # main logic to handle different conversation formats if isinstance (conversation, list ) and all ( isinstance (i, dict ) for i in conversation): As of transformers v4.44, default chat template is no longer allowed, so you must provide a chat template if. But recently when i try to run it again it suddenly errors:attributeerror: Specifically, the prompt templates do not seem to fit well with glm4, causing unexpected behavior or errors. My data contains two key. I tried to solve it on my own but. Verify that your api key is correct and has not expired. Result = handle_single_conversation(conversation) file /data/lizhe/vlmtoolmisuse/glm_4v_9b/tokenization_chatglm.py, line 172, in. 微调脚本使用的官方脚本,只是对compute metrics进行了调整,不应该对这里有影响。 automodelforcausallm, autotokenizer, evalprediction, Cannot use apply_chat_template () because tokenizer.chat_template is not set. My data contains two key. But recently when i try to run it again it suddenly errors:attributeerror: This error occurs when the provided api key is invalid or expired. # main logic to handle different conversation formats if isinstance (conversation, list ) and all ( isinstance (i, dict ) for i in conversation): My data contains two key. I am trying to fine tune llama3.1 using unsloth, since i am a newbie i am confuse about the. I am trying to fine tune llama3.1 using unsloth, since i am a newbie i am confuse about the tokenizer and prompt templete related codes and format. Cannot use apply_chat_template () because tokenizer.chat_template is not set. I created formatting function and mapped dataset already to conversational format: Here is how i’ve deployed the models: Raise valueerror(invalid conversation format) content =. The text was updated successfully, but these errors were. This error occurs when the provided api key is invalid or expired. Cannot use apply_chat_template because tokenizer.chat_template is. 微调脚本使用的官方脚本,只是对compute metrics进行了调整,不应该对这里有影响。 automodelforcausallm, autotokenizer, evalprediction, I created formatting function and mapped dataset already to conversational format: Query = 你好 inputs = tokenizer. Below is the traceback from the server: As of transformers v4.44, default chat template is no longer allowed, so you must provide a chat template if the tokenizer does not. Specifically, the prompt templates do not seem to fit well with glm4, causing unexpected behavior or errors. The issue seems to be unrelated to the server/chat template and is instead caused by nans in large batch evaluation in combination with partial offloading (determined with llama. But recently when i try to run it again it suddenly errors:attributeerror: Import os os.environ ['cuda_visible_devices'] = '0' from. Cannot use apply_chat_template () because tokenizer.chat_template is not set. Raise valueerror(invalid conversation format) content = self.build_infilling_prompt(message) input_message = self.build_single_message(user, ,. 'chatglmtokenizer' object has no attribute 'sp_tokenizer'. Result = handle_single_conversation(conversation) file /data/lizhe/vlmtoolmisuse/glm_4v_9b/tokenization_chatglm.py, line 172, in.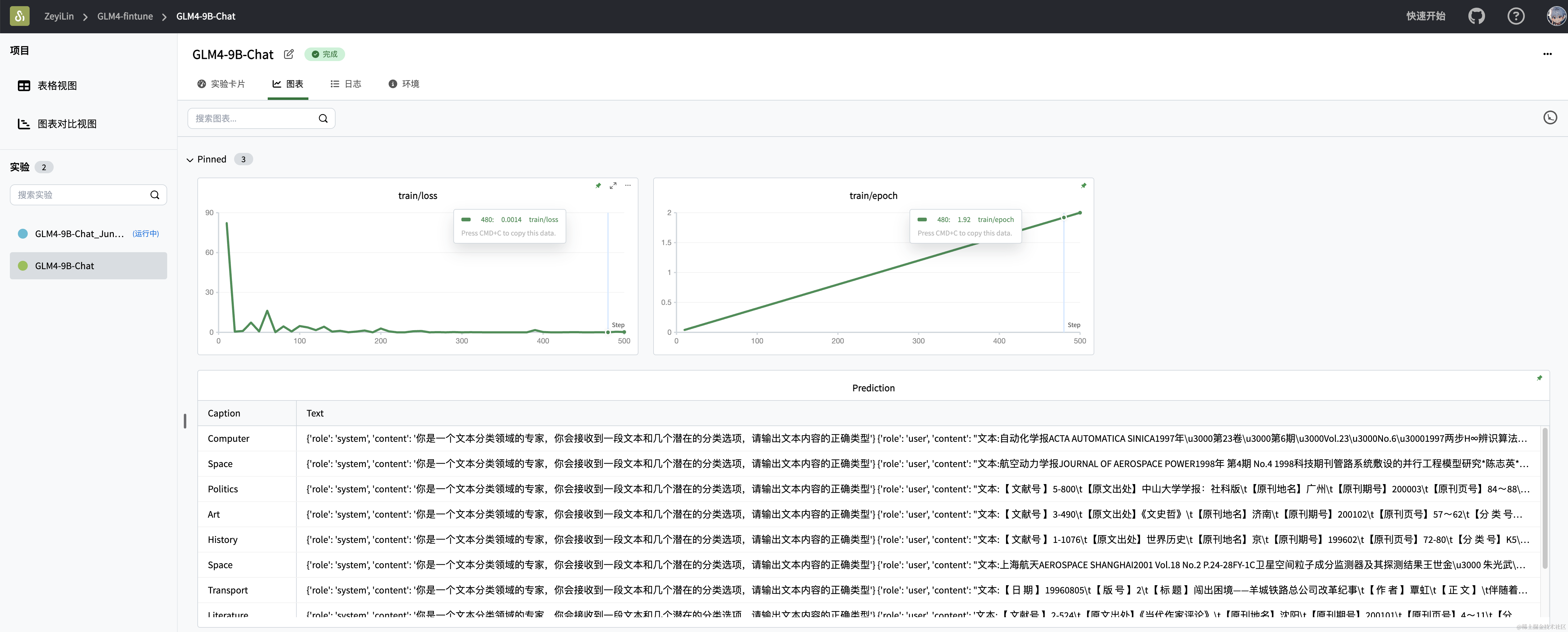
GLM4大模型微调入门实战(完整代码)_chatglm4 微调CSDN博客
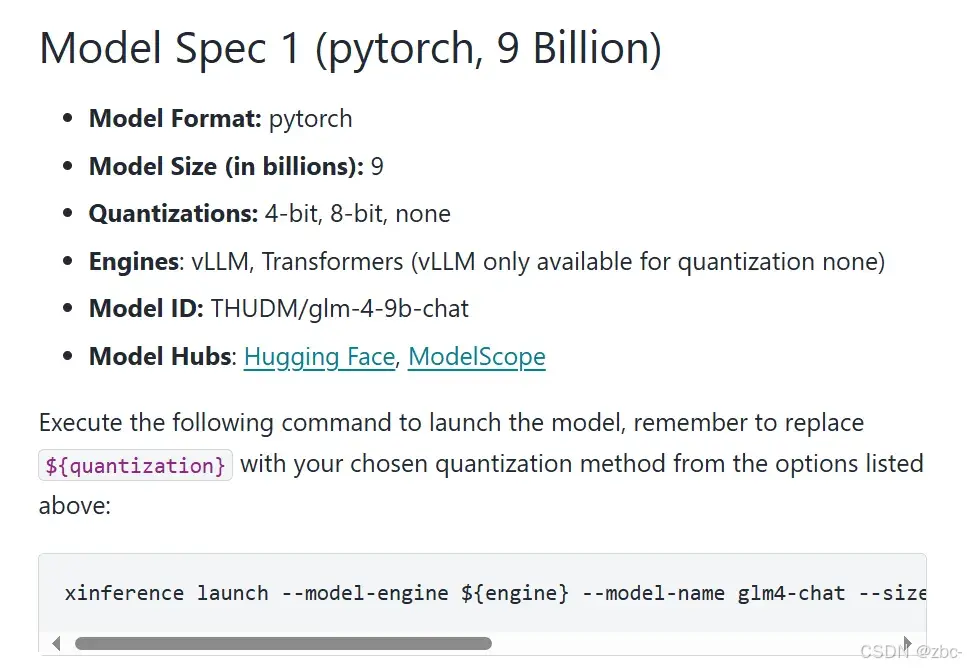
无错误!xinference部署本地模型glm49bchat、bgelargezhv1.5_xinference加载本地模型CSDN博客
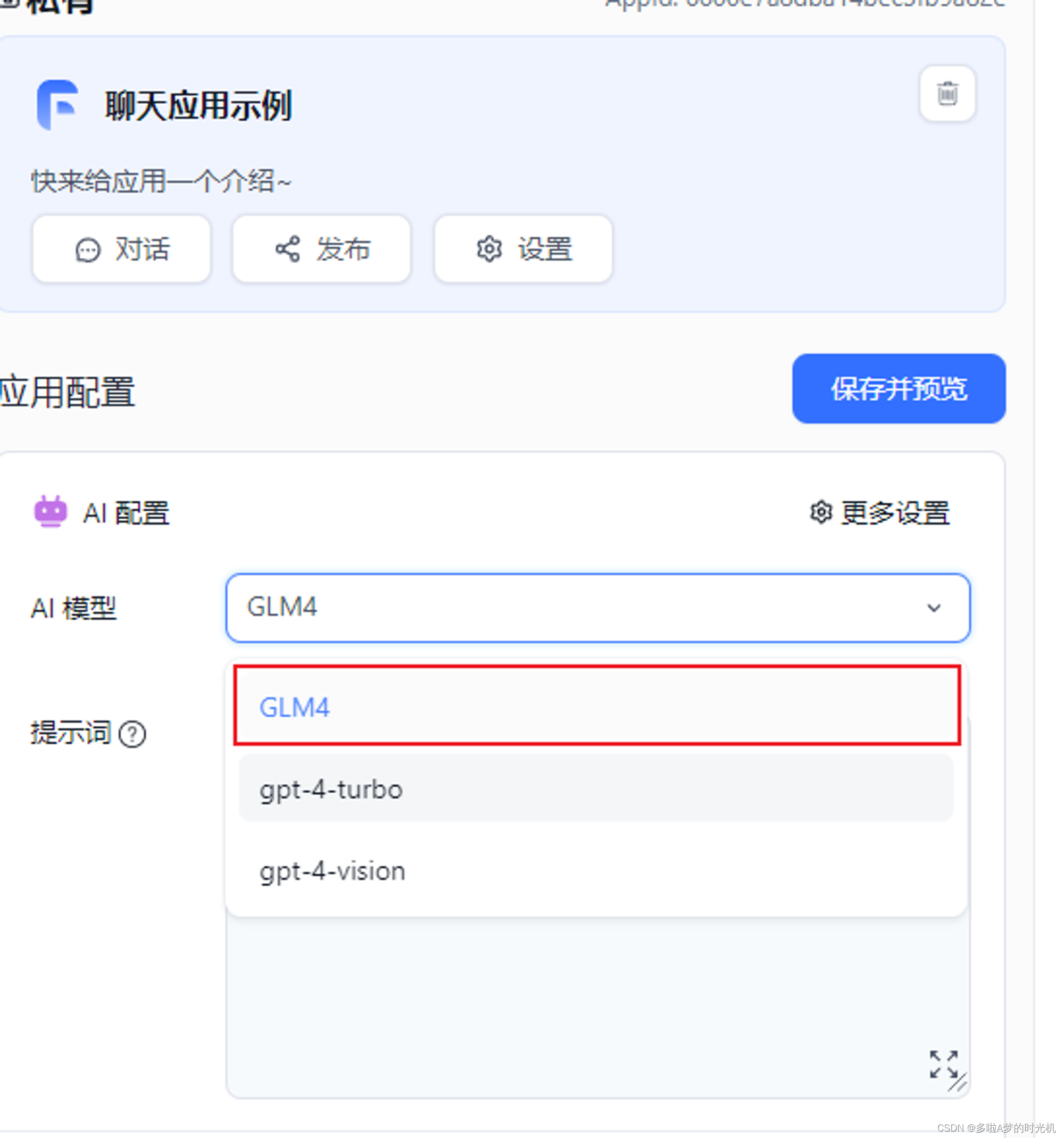
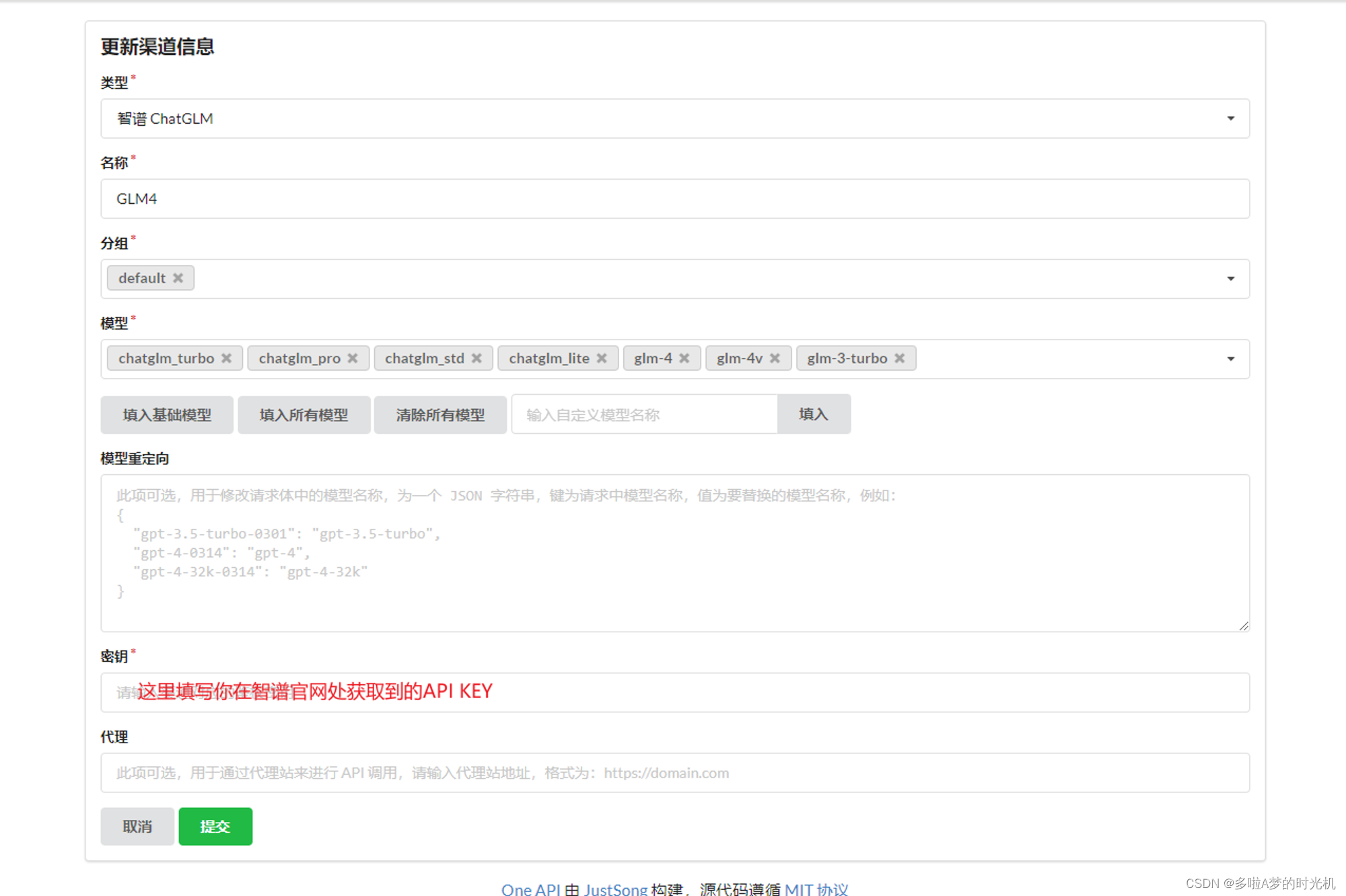
GLM4实践GLM4智能体的本地化实现及部署_glm4本地部署CSDN博客
GLM4实践GLM4智能体的本地化实现及部署_glm4本地部署CSDN博客

【机器学习】GLM49BChat大模型/GLM4V9B多模态大模型概述、原理及推理实战CSDN博客
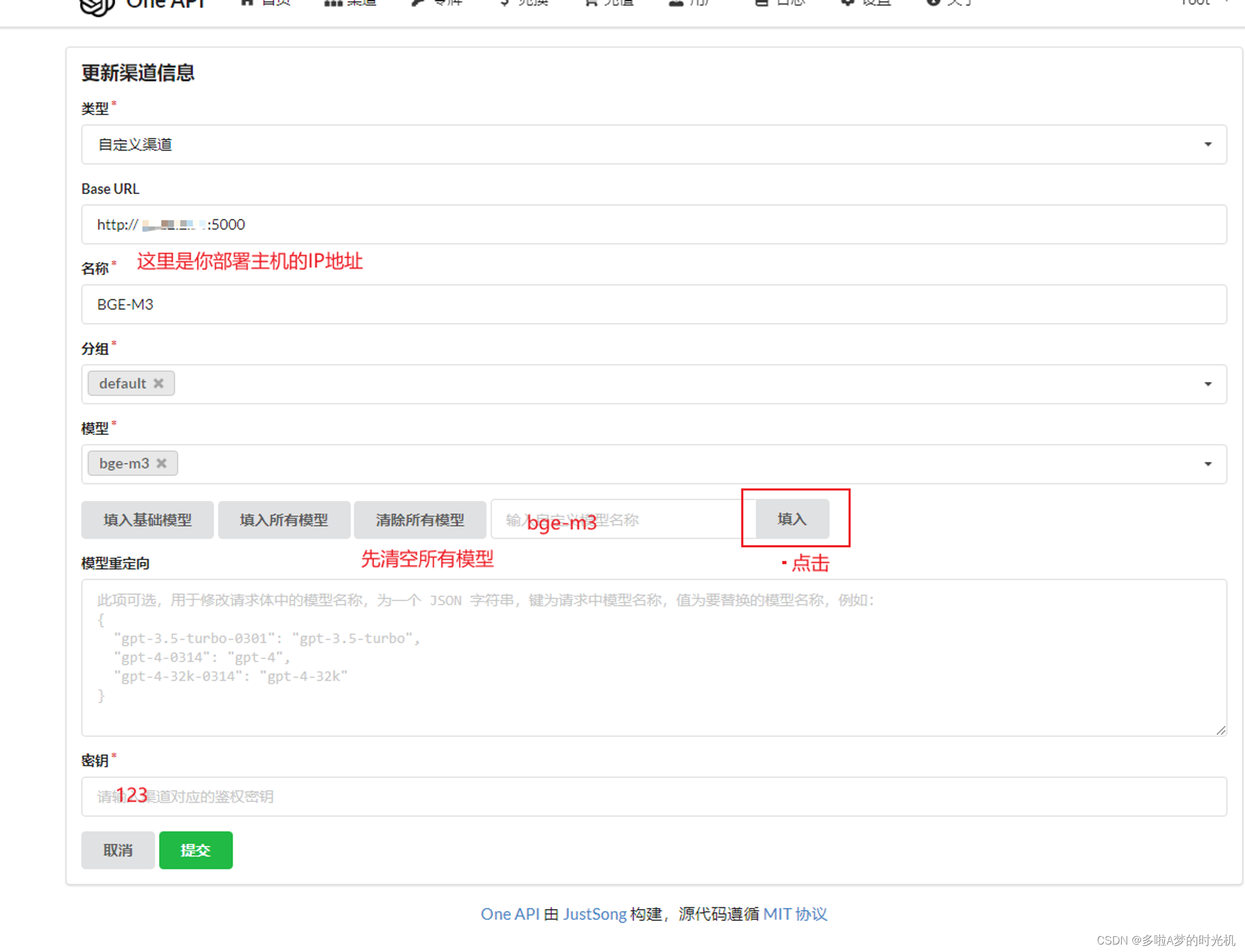
GLM4实践GLM4智能体的本地化实现及部署_glm4本地部署CSDN博客

GLM4实践GLM4智能体的本地化实现及部署_glm4本地部署CSDN博客

GLM4大模型微调入门实战命名实体识别(NER)任务_大模型ner微调CSDN博客

GLM4指令微调实战(完整代码)_自然语言处理_林泽毅kavin智源数据社区

GLM49BChat1M使用入口地址 Ai模型最新工具和软件app下载
I Tried To Solve It On My Own But.
My Data Contains Two Key.
Obtain A New Key If Necessary.
Union[List[Dict[Str, Str]], List[List[Dict[Str, Str]]], Conversation], # Add_Generation_Prompt:
Related Post: