Type Token Ratio Template
Type Token Ratio Template - By default, n = 1,000. But a lot of these words will be repeated, and there may be only say. By default, n = 1,000. It combines number of different words and word type to calculate the rati. They are defined as the ratio of unique tokens divided by the. Analyze text richness and complexity in seconds. The average word frequency (awf) is tokens divided by types or 1/ttr. Wordlist offers a better strategy as well: By default, n = 1,000. For the cat in the hat, ttr =. Ttr = (number of types / number of tokens) context. They are defined as the ratio of unique tokens divided by the. Analyze text richness and complexity in seconds. But a lot of these words will be repeated, and there may be only say. The standardised type/token ratio (sttr) is computed every n words as wordlist goes through each text file. The standardised type/token ratio (sttr) is computed every n words as wordlist goes through each text file. My personal favorite method is type token ratio for semantic skills (ttr). By default, n = 1,000. By default, n = 1,000. For the cat in the hat, ttr =. Ttr is intended to account for language samples of. The tool provides summary information regarding modes of communication used and prompt levels in addition to more traditional language sampling data such as mean length. The standardised type/token ratio (sttr) is computed every n words as wordlist goes through each text file. The standardised type/token ratio (sttr) is computed every n. They are defined as the ratio of unique tokens divided by the. By default, n = 1,000. But a lot of these words will be repeated, and there may be only say. A 1,000 word article might have a ttr of 40%; Ttr is intended to account for language samples of. The number of unique words in a text is often referred to as the. Analyze text richness and complexity in seconds. Ttr = (number of types / number of tokens) context. They are defined as the ratio of unique tokens divided by the. It combines number of different words and word type to calculate the rati. The average word frequency (awf) is tokens divided by types or 1/ttr. The number of unique words in a text is often referred to as the. It combines number of different words and word type to calculate the rati. Ttr = (number of types / number of tokens) context. Analyze text richness and complexity in seconds. The tool provides summary information regarding modes of communication used and prompt levels in addition to more traditional language sampling data such as mean length. Ttr is intended to account for language samples of. By default, n = 1,000. Type/token ratio (ttr) is the percent of total words that are unique word forms. A 1,000 word article might have a. Wordlist offers a better strategy as well: A 1,000 word article might have a ttr of 40%; The standardised type/token ratio (sttr) is computed every n words as wordlist goes through each text file. The number of unique words in a text is often referred to as the. Ttr is intended to account for language samples of. Type/token ratio (ttr) is the percent of total words that are unique word forms. Ttr = (number of types / number of tokens) context. The standardised type/token ratio (sttr) is computed every n words as wordlist goes through each text file. By default, n = 1,000. This is a template created for a language. My personal favorite method is type token ratio for semantic skills (ttr). But a lot of these words will be repeated, and there may be only say. The number of unique words in a text is often referred to as the. The standardised type/token ratio (sttr) is computed every n words as wordlist goes through each text file. In other. Wordlist offers a better strategy as well: Type/token ratios and the standardised type/token ratio if a text is 1,000 words long, it is said to have 1,000 tokens. A 1,000 word article might have a ttr of 40%; The standardised type/token ratio (sttr) is computed every n words as wordlist goes through each text file. The standardised type/token ratio (sttr). A 1,000 word article might have a ttr of 40%; The average word frequency (awf) is tokens divided by types or 1/ttr. My personal favorite method is type token ratio for semantic skills (ttr). But a lot of these words will be repeated, and there may be only say. By default, n = 1,000. They are defined as the ratio of unique tokens divided by the. The standardised type/token ratio (sttr) is computed every n words as wordlist goes through each text file. Analyze text richness and complexity in seconds. It combines number of different words and word type to calculate the rati. By default, n = 1,000. By default, n = 1,000. The number of unique words in a text is often referred to as the. The standardised type/token ratio (sttr) is computed every n words as wordlist goes through each text file. The standardised type/token ratio (sttr) is computed every n words as wordlist goes through each text file. This is a template created for a language. My personal favorite method is type token ratio for semantic skills (ttr). A 1,000 word article might have a ttr of 40%; For the cat in the hat, ttr =. Ttr = (number of types / number of tokens) context. The average word frequency (awf) is tokens divided by types or 1/ttr. Ttr is intended to account for language samples of.
PPT LIN 3098 Corpus Linguistics Lecture 5 PowerPoint Presentation

Typetoken ratio as a function of time for eight languages (including
An example image of the type/token ratio (TTR) for the "Audio
typetokenratio.pdf Lexicon Vocabulary

PPT LIN 3098 Corpus Linguistics Lecture 5 PowerPoint Presentation

PPT LIN 3098 Corpus Linguistics Lecture 5 PowerPoint Presentation

TypeToken Ratio

Determining The Typetoken Ratio. Pinned by SOS Inc. Resources
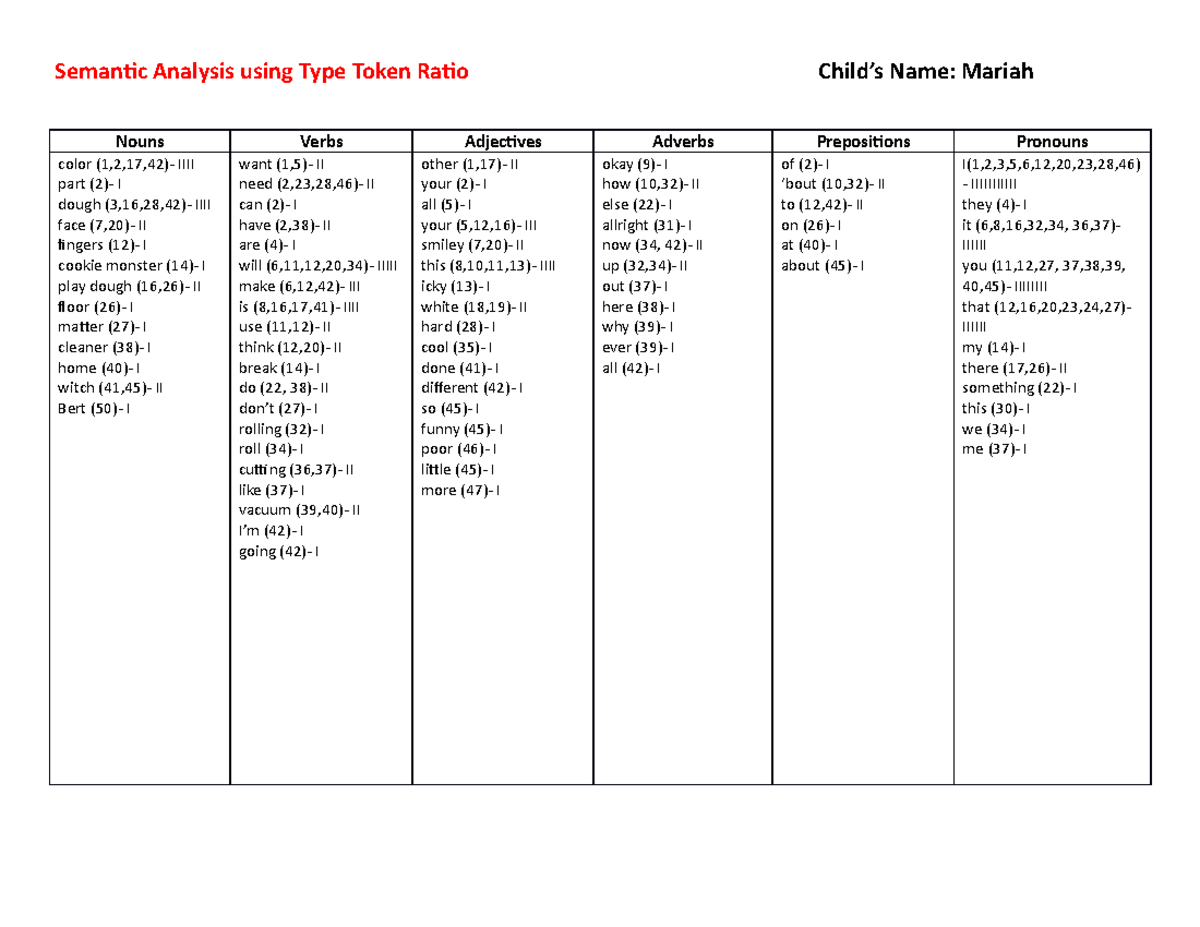
LSA Semantics Type Token Ratio form Semantic Analysis using Type

Language Sample Analysis Part 2 of 4 TypeToken Ratio (DEEP DIVE) and
Type/Token Ratios And The Standardised Type/Token Ratio If A Text Is 1,000 Words Long, It Is Said To Have 1,000 Tokens.
In Other Words The Ratio Is Calculated For The First 1,000.
Type/Token Ratio (Ttr) Is The Percent Of Total Words That Are Unique Word Forms.
The Tool Provides Summary Information Regarding Modes Of Communication Used And Prompt Levels In Addition To More Traditional Language Sampling Data Such As Mean Length.
Related Post:
